The Kolmogorov-Smirnov test (KS test) is a test which allows you to compare two univariate, continuous distributions by looking at their CDFs. Such CDFs can both be empirical (two-sample KS) or one of them can be empirical, and the other one built parametrically (one-sample).
Client: Good Evening.
Bartender: Good evening. Rough day?
Client: I should have stayed in bed…
Bartender: Maybe we have just the right thing for you. How about a Kolmogorov-Smirnov?
Client: Make it two-sample, please.
The null hypothesis for the one-sample case is that the empirical distribution is drawn from the reference distribution (which is usually parametric). For the two-sample test, the null hypothesis is that the two samples were drawn from the same distribution.
What the actual value of the KS statistic is the highest of all differences between the CDFs in the test. An expression for this statistic is:

Sometimes in the literature, it is not uncommon to see it expressed like this:

Some of you may have spotted the similarity between this expressions, and the Glivenko-Cantelli theorem (a.k.a. the fundamental theorem of probability by some people). To refresh it a bit, here is Glivenko-Cantelli for you:

And notice the “almost surely”. And “almost surely” will have to do. Because this theorem is such a cornerstone of statistics. And other people have made some interesting discoveries around Glivenko-Cantelli. For instance, the DKW inequality draws bounds on the convergence of Glivenko-Cantelli by bounding the probability that the 
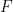
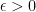
And well, if you simply want to start playing with the KS statistic, there is a short code snippet in our notebook that you can use to start comparing samples to each other and samples to DF contained in the stats package of scipy.
Enjoy!
The featured image was taken from here.
