<Disclaimer: my opinions are my own. Situations depicted in this blog are not intended to depict any former, current or future employer, or any particular person or minority>
Nature is beautiful. Can we make sense of the forest while still keeping track of the sick trees? Forest Photo by Jeroen Bendeler on StockSnap
Tuesday morning. You get a cup of <insert beverage> and zombie-shuffle your way into your desk. After opening emails, you see it is now possible to access that awesome dataset (which is totally necessary for world domination improving your segmentation scores!).
Soon you notice a catch: this dataset is undocumented, as-is provided and Humongous (the term Big Data chocked on a tide pod last decade). But at least the names are self-explanatory and they include units. Alright. Exploratory analysis commences: ranges, missing values, duplicates, and all endemic critters in between get pulled. You throw in univariate quantiles and a correlation matrix for good measure. We have now learned a thing or two about this dataset.
While exploring some more, there seem to be some things unexpectedly off with this dataset. Like, values that are physically impossible but there they are. Or things that could *in principle* be valid values but are not. Or things that you can see how they got to be logged the way they are, but the circumstances around it are hard to track.
Unsure of how to proceed, you reach back to the maintainer of this dataset. It is a person (yay!) that agrees on the fact that the data is undocumented (ok?), adds that it will not be documented anytime soon (oh…) then sends you home with a few pointers and gotchas.
Formula does not parse
What are we supposed to do now? ignore all data quality problems? refuse to do anything until we are sure its clean? Is this data wrong?
Let’s take this last rhetoric question and rephrase it into something measurable: HOW MUCH can you expect this data to be wrong? Most importantly: What is your level of confidence that your estimation of data “wrongness” is within a range that you deem as “workable”?
Enter: Binomial proportions, confidence intervals, margins of error. In this post, we show how a sample can be used to assess the percentage of your data affected by the kind of data quality problems which are otherwise expensive to detect over an entire dataset, using confidence intervals over binomial proportions.
Binomial proportions emerge when we make 


You can quickly see how can binomial proportions be useful for modelling data quality: If you allow the presence (or not) of a failure in a section in your dataset to be modeled as an independent Bernoulli trial in which every
Binomial Distributions have two parameters:
Now we know that
With a confidence interval over a binomial proportion 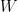
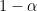

Now, you do know how big your dataset is (sort of). You can pick some expression for confidence intervals of binomial proportions that accepts some parameters reflecting the inner struggles of how “wrong” do you expect this dataset to be (e.g. desired confidence levels and margins of error) and use this expression to extract a sample size.
When you look at the many methods available for estimating confidence intervals in binomial proportions, you can quickly notice that an underlying assumption in many of these methods is that the size of your dataset (number of Bernoulli trials) is sufficiently big, so again, references to the central limit theorem are made, which allows connecting the expected value of the proportion of defects of a sample, with that of the entire dataset, and with some Z score (derived from Standard Normal Gaussians). You can use the knowledge from your exploratory analysis to get a grasp of which of these methods should NOT be used on your dataset.
Now, if you don’t have that kind of time in your hands 🙂 and you have some reasonable information that the errors are non-zero and non-total, you can carry on with a confidence interval expression like this, built with the Wald method:
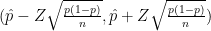
This expression centers our confidence interval in 

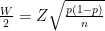
In this context, 
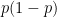
Regarding 
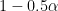
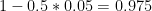
Now, suppose that you really don’t know if you have 2% errors (something you can accept) or 15% (which you probably may not want to work with…). Then you can take 
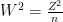
And solving this for 
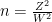
Then feel free to choose how wide do you want your confidence interval
You can get a grasp at sample sizes for the this specific case of

There are a few things that you can already notice. First, the sample size increases drastically from 3% to 2% and then to 1%
Or how would your calculations change if the assumption of the same probability of error for all parts of your dataset would no longer be reasonable?
Remember that sampling ALWAYS implies some uncertainty. What we are doing here is getting a sample so that we can have some information and decide if its worth our time and effort to continue working with a dataset or not. You can make this an exercise for your enjoyment 🙂 or you can get a quick, reasonable answer before committing even more.
Enjoy! Go say hi to your local Data Person!
